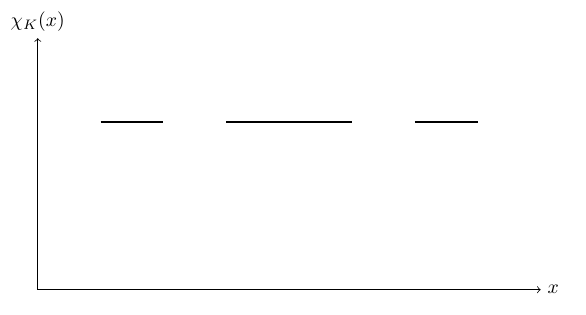实分析补充练习与补充知识点 6.30
设定义在
不妨设
对于有界零测集
设
设存在一列
7.1 补充上面的定理证明:
补充1 Fatou-Lebesgue定理 对于给定的度量空间
补充2 各种收敛性 考试可能涉及到各种收敛性,这里做出一定总结:
引理1 若Egorov定理
证明我看过一遍了,要用到上面的引理。取定
注意
在
定理
由上述引理1立即得证。
Riesz定理 依测度收敛序列存在几乎处处收敛子列。
补充3 Lusin定理 Lusin定理描述了可测函数和连续函数的关系。其叙述如下:
首先我们需要知道,对于可测函数简单紧支函数列
推论1
推论2
7.2
设
证明:等价于证明级数
补充4 基本换元 对
补充5 控制收敛定理相关 首先,DCT证明了更强的
推论1(逐项积分)
不同于非负可测函数列的逐项积分定理,这里的表述是:
设推论2(积分号下求导)
补充6 可积函数与连续函数的关系
补充7 重积分与累次积分 Fubini定理和Tonelli定理部分在周民强上已经过了一遍了,就不在这里写了
7.3 补充8 不定积分的微分 引理2 设
Lebesgue微分定理(一维版本) 设
证明:
step1,
step2,因为
step3,证明
推论 若
证明:将Lebesgue微分定理应用于函数
补充9 绝对连续函数
定义 对于定义在
AC函数是一致连续且有界变差的;
如果
微积分基本定理成立;
如果
如果
若
绝对连续函数有着强于有界变差函数的结论:
定理 如果
暂时更新到这里,剩下的时间要回顾stein上的习题,再就泡在周民强里面了。晚上争取把chap2的习题全都过一遍。